Llama3.1论文阅读
7月23日,meta发了Llama3.1的论文,通过huggingface,可以到meta最新博客的末尾找到论文的链接。 我主要关心其中基础设施相关的部分,尤其是和网络有关的地方,这里简单记录一下。
概述
在论文的3.3章节,Infrastructure, Scaling, and Efficiency,开始介绍他们这次训练使用的基础设施架构。这里主要就关注下网络部分。
网络架构
- 这次的405B模型在 16K H100 GPUs上训练,这个规模是之前最大的规模
- 每台服务器配备八个 GPU 和两个 CPU。在一台服务器内,八个 GPU 通过 NVLink 连接
- 使用RoCE网络
- Minipack2 Open Compute Project 作为接入交换机,是一种
- 汇聚交换机用的 Arista 7800
- 所有机间互联都用的 400G
- 网络拓扑是三层 Clos 结构,每台服务器8张卡,每个机架2台服务器接入Minipack2,中间用192台汇聚算作一个pod,共计3072张卡
- 8个pod组成整个集群,一共24000卡,pod上联收敛比是1:7,原因是他们优化了模型的并行策略,大幅度减少了跨pod的流量传输
Arista 7800介绍:一种深缓存交换机,提供最大400G接入 Minipack2 的资料找不到,不过在 Arista 的说明中有400G接入
负载均衡
负载均衡用了两种优化:
First, our collective library creates 16 network flows between two GPUs Second, our Enhanced-ECMP (E-ECMP) protocol effectively balances these 16 flows across different network paths by hashing on additional fields in the RoCE header of packets.
meta对负载均衡没有做更多的创新,只是进行了调优,为GPU之间建立了16个流,并且在RoCE头上添加了额外的字段用来打散哈希
拥塞控制
使用了深buffer交换机,使用了 E-ECMP 同时关闭了QCQCN,这样可以避免网络拥塞
并行策略
The order of parallelism dimensions, [TP, CP, PP, DP], is optimized for network communication.
并行策略用了4种,比常见的多了一种上下文并行,整体如下图:  越内部的并行策略通信量越大,基本都控制在机内是上下文并行和张量并行;而机件是数据并行和流水线并行这两种。合理的并行策略也是网络通信优化的一种。
越内部的并行策略通信量越大,基本都控制在机内是上下文并行和张量并行;而机件是数据并行和流水线并行这两种。合理的并行策略也是网络通信优化的一种。
集合通信
提供了一个粗略的数据,PP 和 DP 可能通过多跳网络进行通信,延迟高达几十微秒。所以他们在自己的集合通信库NCCLX里做了一些优化。在PP中需要点点对的通信,需要反复传递大量的控制信息(我理解是创建QP),meta主要做了两件事:一个是调整了数据分块的方式(可能是合并小数据包),另外一个是提升小的控制包的传输优先级防止被数据包阻塞。
故障
meta给出了一张故障占比表 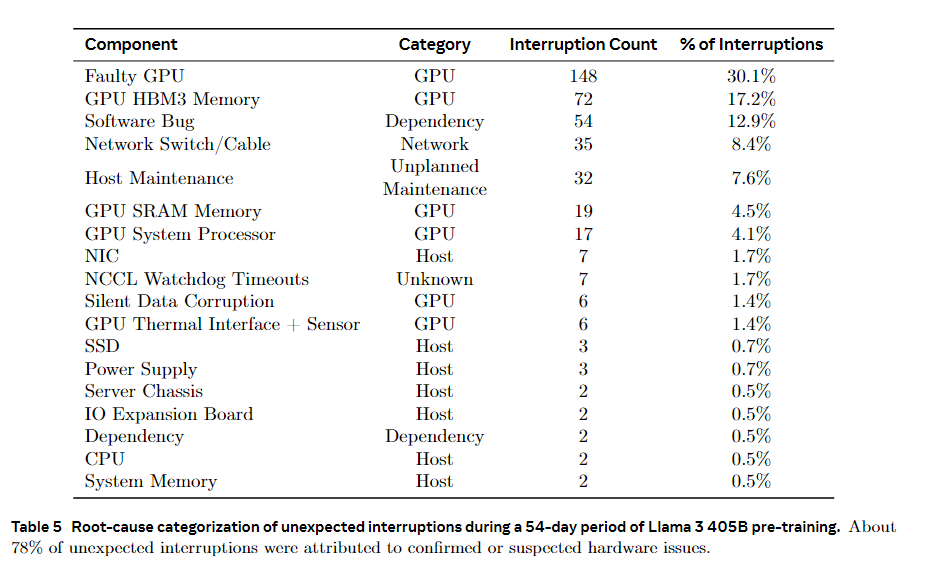 可以看到大部分是硬件导致的,其中网络方面的:交换机8.4%,网卡1.7%。这里的NIC应该就是指HPC,不知道为啥他要叫NIC。
可以看到大部分是硬件导致的,其中网络方面的:交换机8.4%,网卡1.7%。这里的NIC应该就是指HPC,不知道为啥他要叫NIC。
其他
这里还提到RoCE和NVlink混合使用对调试带来了很大的麻烦,主要是RDMA和CUDA联动的时候的问题,具体是什么不知道。
总结
meta这次发布的Llama3.1参数达到了402B,整个训练集群也到了2w+卡的程度,但是在网络上主要还是调优为主。但是在网络相关的软件上下了功夫,包括感知网络架构以减少跨pod流量,调整数据分块方式以及提升控制包优先级等等。