Alibaba HPN 7.0论文阅读
Alibaba HPN 7.0论文阅读
最近在做网络拓扑架构的工作,阿里的HPN7.0的论文给了我一个样板,这里简单记录下阅读的心得。
背景
背景这块,HPN还是说了两个大家熟知的问题:
- 低熵导致哈希冲突严重
- 云网络中,单个流占NIC的带宽最大也就20%,而LLM训练则可以打满
- LLM的网络模型是阶段性冲高的心跳模式
- 单点故障影响训练效率
- 单点故障可能导致整体训练停止
- 训练停止的整体折损费用大概比云网络高20%
- 训练过程中checkpoint开销很大,单GPU大概30G,一次100秒(这两个数字是举例说明的,不确定是否为统计值)
- 每小时训练成本2万美元,使用3k GPU,一次失败可能损失3万美元
- NIC-TOR故障每个月大概0.057%,Tor交换机每月0.051%概率故障
整体架构
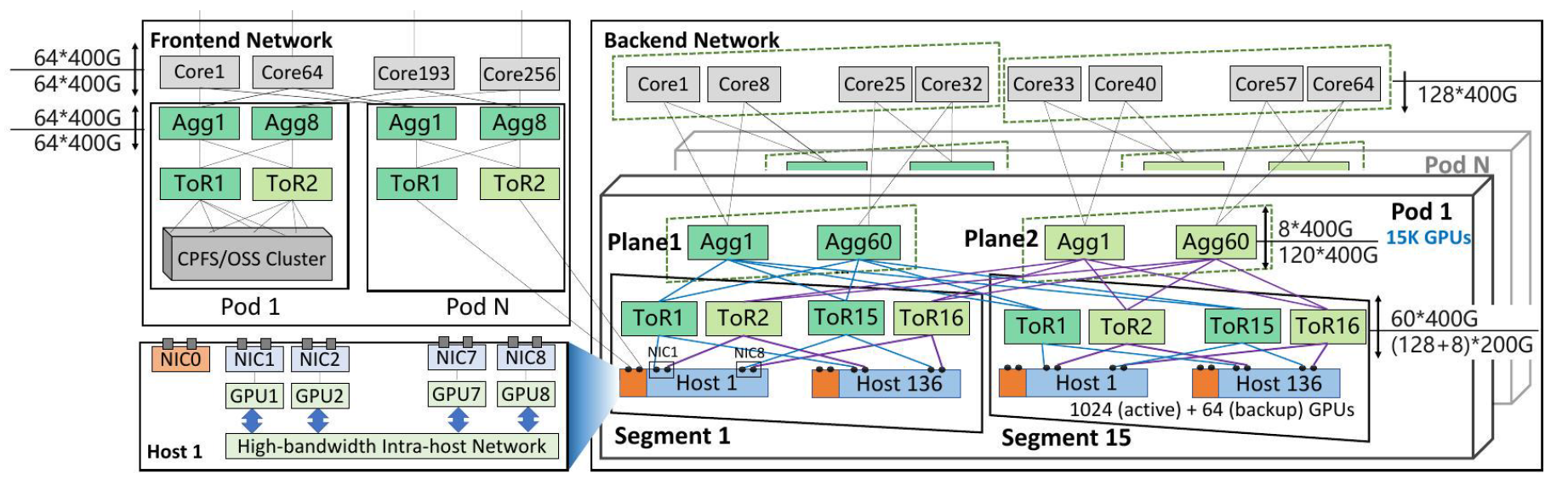
机内互联
没有提很多,给了一个数据:可以支撑机内双向400GBps-900GBps的数据传输。
RDMA网络
存储训练分离,服务器单独提供一张网卡连接到存储的网络中,不与训练共用网络带宽。
这里提到一个数据,大部分训练(96.3%)使用少于1kGPU,所以他们将1k作为一个单层网络的设计规模。
其他比较关键的有以下点:
- 双平面,关键就是端侧一分二,400Gbps的NIC分别上联两个200Gbps的交换机端口。
- 单POD内冗余,采用1.067:1的收敛比,获得pod内的冗余。
- 规模,可以支撑16K的GPU,如果考虑继续扩大规模牺牲spine到core的收敛比,那么单个pod可以支撑15k GPU。
去堆叠
好像是经典方案,从锐捷、华三之类的厂商都听过,反而GPU厂商并不喜欢这样做,对他们来说修改NCCL以及机内通信都挺麻烦的。
哈希优化
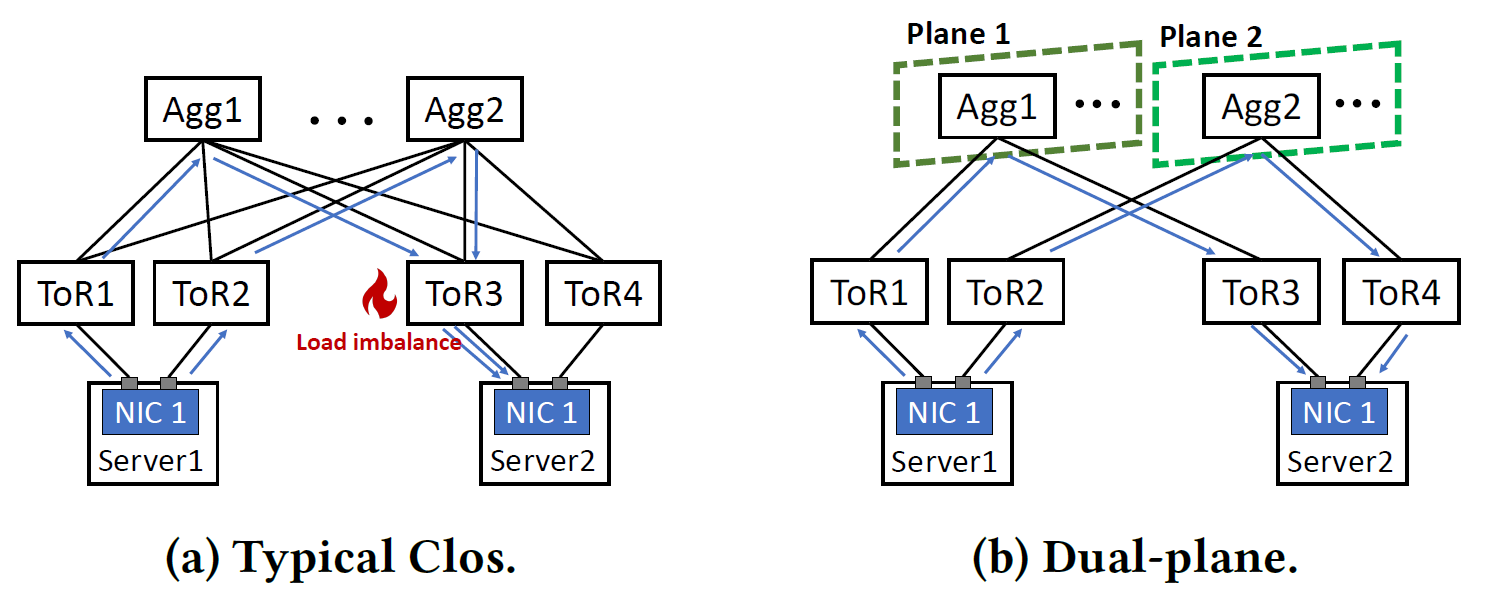 双平面的架构可以解决低熵带来的哈希冲突问题,阿里这里基于双平面架构在ToR上做了优化。如图所示,可以看到左边存在两路流通过同一个平面通信,导致server2出现流量不均衡的情况,而右边ToR2因为不与平面1中的agg相连,所以就不会产生这个问题。 至于平面2中多个agg选哪一个则是根据遥测进行规划,ToR2到agg2有60条路径,O(60)的复杂度可以选择流量更小的一条路线。 这里还给出了一个哈希计算复杂度的对比:
双平面的架构可以解决低熵带来的哈希冲突问题,阿里这里基于双平面架构在ToR上做了优化。如图所示,可以看到左边存在两路流通过同一个平面通信,导致server2出现流量不均衡的情况,而右边ToR2因为不与平面1中的agg相连,所以就不会产生这个问题。 至于平面2中多个agg选哪一个则是根据遥测进行规划,ToR2到agg2有60条路径,O(60)的复杂度可以选择流量更小的一条路线。 这里还给出了一个哈希计算复杂度的对比: 
其他网络
基本属于传统设计,提到了存储集群由 96-128 个存储主机组成,运行 CPFS 和 OSS 存储服务,提供推理能力。
一些结论
- 阿里没有整张网络测试,只在2300多卡的小规模集群上测试了下,提升挺大的
- 在1k卡的测试中,带宽利用率上去了(理所当然的,毕竟都不设计哈希冲突)
感受
之前从来没想过端侧可以一拆二,这个设计因为一拆二的原因网络规模扩大了两倍,由此可以联想到是否可以一拆4(现阶段估计技术不行,包括bond之类的)。另外提到的一些并没有很多新鲜东西,不过确实是给了一些测试数据,不过这些数据对我的工作也没太大作用。
本文由作者按照 CC BY 4.0 进行授权