给朋友介绍现在流行的AI技术原理
最近朋友跟我抱怨说使用AI的时候 ,有时候觉得AI很蠢,有时候又觉得AI很厉害,然后他们单位自身也推出了自有的AI服务,她不知道这个与公开的AI有什么区别,因此想写下来我对AI的粗浅理解,希望可以给行外人一些好理解但是可能不那么正确的解释。
现在的AI是一种”大力出奇迹“的技术
最简单的AI模型
从一个简单的数学开始,现在有一个简单的数学公式:y=ax+b,这是一个线性函数,可以用来描述一个直线,如图所示: 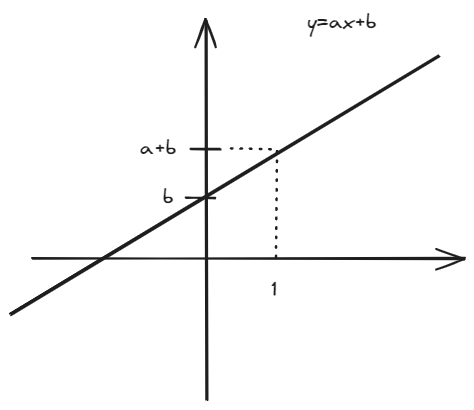 假如这是描述下雨的情况,x是乌云的数量,y是下雨的时间,我们通过观察发现当x=1时,y=1,当x=2时,y=2,当x=3时,y=3,那么我们可以得到a=1,b=0,这就是一个很简单的“AI模型”,这个模型包含两个参数:
假如这是描述下雨的情况,x是乌云的数量,y是下雨的时间,我们通过观察发现当x=1时,y=1,当x=2时,y=2,当x=3时,y=3,那么我们可以得到a=1,b=0,这就是一个很简单的“AI模型”,这个模型包含两个参数:
- a:1,乌云的数量和下雨时间的关系
- b:0,下雨的时间
我们可以通过输入乌云的数量,就可以得到下雨的时间了。
扩展一下
现在,稍微扩展一下,我们需要一个模型,用来识别一张图片是猫还是狗,首先我们抽象这张图片。大家都知道图片有一个属性是像素,像素的意思就是它是有多少个“点”构成的,假如我们的图片是一个16*16的小图片,如图: ![]() 从属性上看,我这个logo是一个小的图片,它有256个像素点,每个像素点是一个RGB值,所以我可以用一个[$x_1,x_2,x_3,\ldots,x_{256}$],每个x的范围是1-255,就可以用来描述这个图片。为了接受这个长达256个x输入,我们修改公式为: \(y=a_1x_1+a_2x_2+\ldots+a_{256}x_{256}+b\) 同时,因为我们的目标是要判断图片是猫还是狗,我需要让y的值控制为0-1之间,这个时候我们就需要一个激活函数,这个激活函数的作用就是把y的值控制在0-1之间,这个激活函数的名字叫做sigmoid函数,它的公式是:
从属性上看,我这个logo是一个小的图片,它有256个像素点,每个像素点是一个RGB值,所以我可以用一个[$x_1,x_2,x_3,\ldots,x_{256}$],每个x的范围是1-255,就可以用来描述这个图片。为了接受这个长达256个x输入,我们修改公式为: \(y=a_1x_1+a_2x_2+\ldots+a_{256}x_{256}+b\) 同时,因为我们的目标是要判断图片是猫还是狗,我需要让y的值控制为0-1之间,这个时候我们就需要一个激活函数,这个激活函数的作用就是把y的值控制在0-1之间,这个激活函数的名字叫做sigmoid函数,它的公式是:
为什么要用sigmoid函数?因为sigmoid函数的值域是0-1,这个和我们的目标是一致的,所以我们可以用这个函数来控制y的值域。
所以,我们的模型就变成了: \(y=\sigma(a_1x_1+a_2x_2+\ldots+a_{256}x_{256}+b)\)
假如我手头有大量的图片,一开始我们设置所有的参数($a_1,a_2,\ldots,a_{256},b$)都是随机的,然后我们把这些图片输入到我们的模型中,我们可以得到一些y值,假如我们设置图片是猫则y=1,如果是狗则y=0,那么值越接近1,它更有可能是猫图,值越接近0,它更有可能是狗。 这个时候我们的输入得到不同的y值,这个y值可能与我们的预期不符,它明明是一个猫,我们的模型却更认为它是狗,那么我们需要做的就是修改参数($a_1,a_2,\ldots,a_{256},b$),使得y值更接近我们的预期。这个就叫做“训练”,而最终我们得到了一组参数,这个参数就是我们的“AI模型”,而这个模型对大量的图片都可以做出正确的判断。
大力出奇迹
我们需要面对更为复杂的场景,我们提一个问题,那么我们需要模型回答我这个问题,最朴素的想法是我们把所有的字都进行编码变成一个一个的数字,那么我们会得到一串数字x,那么我们的数据会告诉我回答是什么,这个答案的字也编码成一个一个的数字y,举个例子:
- 问:2025年2月18日的天气如何?
- 答1:晴天
- 答2:出太阳
- 答3:天晴
- 。。。
我们通过一些列参数和函数最终转换成某个答案,这个过程就是我们的AI模型,而这个模型的参数是通过大量的数据训练出来的,这个过程就是我们的“大力出奇迹”。而现在的大模型都会提规格,比如chatGPT的规格是1750亿个参数,本质上就是通过很多轮的 $y=f(a_1x_1+a_2x_2+\ldots+a_{n}x_{n}+b)$ 来训练出来的。
AI的巧力
人工智能其实有很多模型,现在流行的大模型基本都是基于上述这个基本模型扩展的,我们会构建很多个神经元,每个神经元的输入都是上一系列神经元的输出与某个参数相乘,最终相加得到,神经元内部会构建类似sigmoid函数的激活函数将数据进行调整,最终形成模型。大体上如下图: 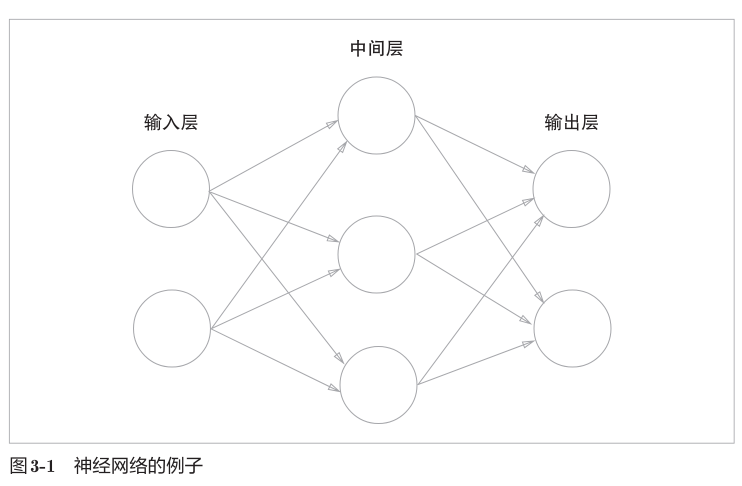 工程师们会设置很多优化点,让参数变得更”正确“,比如:
工程师们会设置很多优化点,让参数变得更”正确“,比如:
- 对输入更合理的建模,比如从单个字编码变成用单个词进行编码
- 使用更多的更正确的数据进行训练
- 增加更多的参数用来描述模型
- 使用一些理所当然的输入输出对模型进行矫正,比如我问天气,你回答天气相关的,而不用回答数学问题
- 。。。 而所有的这一切,都需要更加厉害的算法,更多的算力来做矩阵乘法,更多的数据来训练模型,这就是现在的AI技术。
模型的部署
一个训练好的模型就是大量的参数,我们需要一些强有力的服务器来运行,将我们的输入编码,放到模型进行参数计算(推理),然后对输出进行渲染。当前的deepseek优化了推理过程,减少了计算需求,使得我们的模型可以在更小的服务器上运行,这就是网上所谓的本地化部署。如果模型足够小,算力要求足够低,那么我们的手机也能安装一个自己的AI。
总结
我的观点是当前的大模型技术是一种”大力出奇迹”的技术,现在大量的工作都是在堆叠参数规模增加它的可靠性,或者使用更好的工程能力降低它的训练成本,同时也有很多工程师在研究如何利用大模型强化自己的应用软件,或者赋能日常的生产和生活。